![Good practices for high-performance and scalable Node.js applications [Part 2/3]](https://iquii.com/wp-content/uploads/2018/02/NODE.JS_2_HEADER.jpg "Good practices for high-performance and scalable Node.js applications [Part 2/3]")
Good practices for high-performance and scalable Node.js applications [Part 2/3]
Questo articolo è disponibile in lingua inglese sul nostro canale Medium.
Nel precedente articolo abbiamo visto come scalare orizzontalmente un’applicazione Node.js, senza preoccuparci del codice. In questo capitolo saranno trattati alcuni aspetti che è necessario considerare al fine di prevenire comportamenti indesiderati nel momento in cui i processi vengono istanziati più volte.
Disaccoppiare istanze applicative e database
Il primo punto non riguarda il codice ma l’architettura.
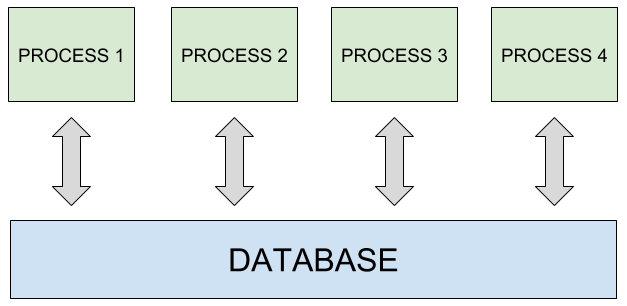
Se si vuole rendere la propria applicazione in condizione di scalare su differenti macchine, è necessario istanziare il proprio DBMS su una macchina indipendente, al fine di poter duplicare a piacimento le istanze applicative.
Fare il deploy di applicazione e database sulla stessa macchina è una scelta economica che può essere utilizzata per scopi di sviluppo, ma non è assolutamente raccomandabile in ambienti di produzione, dove applicativo e database devono poter scalare in modo indipendente. Lo stesso principio si applica a istanze di database in-memory come Redis.
Rendere la propria applicazione stateless
Quando si istanziano processi multipli della propria applicazione, ogni processo avrà il suo proprio spazio di memoria. Questo significa che anche se si utilizza una singola macchina, quando viene memorizzato un valore in una variabile globale, o più comunemente una sessione in memoria, non sarà accessibile se il balancer reindirizza la propria richiesta successiva ad un diverso process.
Questo principio si applica sia ai dati di sessione che a valori interni, come ad esempio le impostazioni globali a livello applicativo. Per valori di questo genere che possono cambiare durante l’esecuzione dell’applicazione, la soluzione è di memorizzarli sul database esterno (sia questo su disco o in memoria) al fine di renderli accessibili allo stesso modo da tutti i processi.
Autenticazione stateless con JWT
L’autenticazione è uno dei primi argomenti da considerare quando si intende sviluppare un’applicazione stateless. Se si memorizzano le sessioni in memoria, queste saranno contestualizzate in quel singolo processo.
Per rimediare a questo problema bisognerebbe configurare il proprio load balancer di rete in modo tale che lo stesso utente venga indirizzato sempre sulla stessa macchina, ed il load balancer applicativo affinchè questa affinità riguardi anche il singolo processo (sticky sessions).
Una soluzione triviale a questo problema è di impostare il metodo di memorizzazione delle sessioni in qualcosa di più persistente, come ad esempio il DB. Se però l’applicativo necessita di verificare i dati di sessione su ogni richiesta, si avranno operazioni di I/O su disco per ogni chiamata API ricevuta, cosa che probabilmente non giova alle performance.
Una soluzione leggermente migliore e veloce (se permessa dal proprio framework di autenticazione) è di memorizzare le sessioni in un database in-memory come Redis. Un’istanza Redis di solito è esterna e indipendente come il Database, con la differenza di essere molto più veloce lavorando in RAM. Il problema di questo approccio è la necessità di spazio di memoria crescente all’aumentare delle sessioni contemporanee.
Se si cerca un approccio più efficiente per un’autenticazione stateless, si può dare un’occhiata ai JSON Web Token.
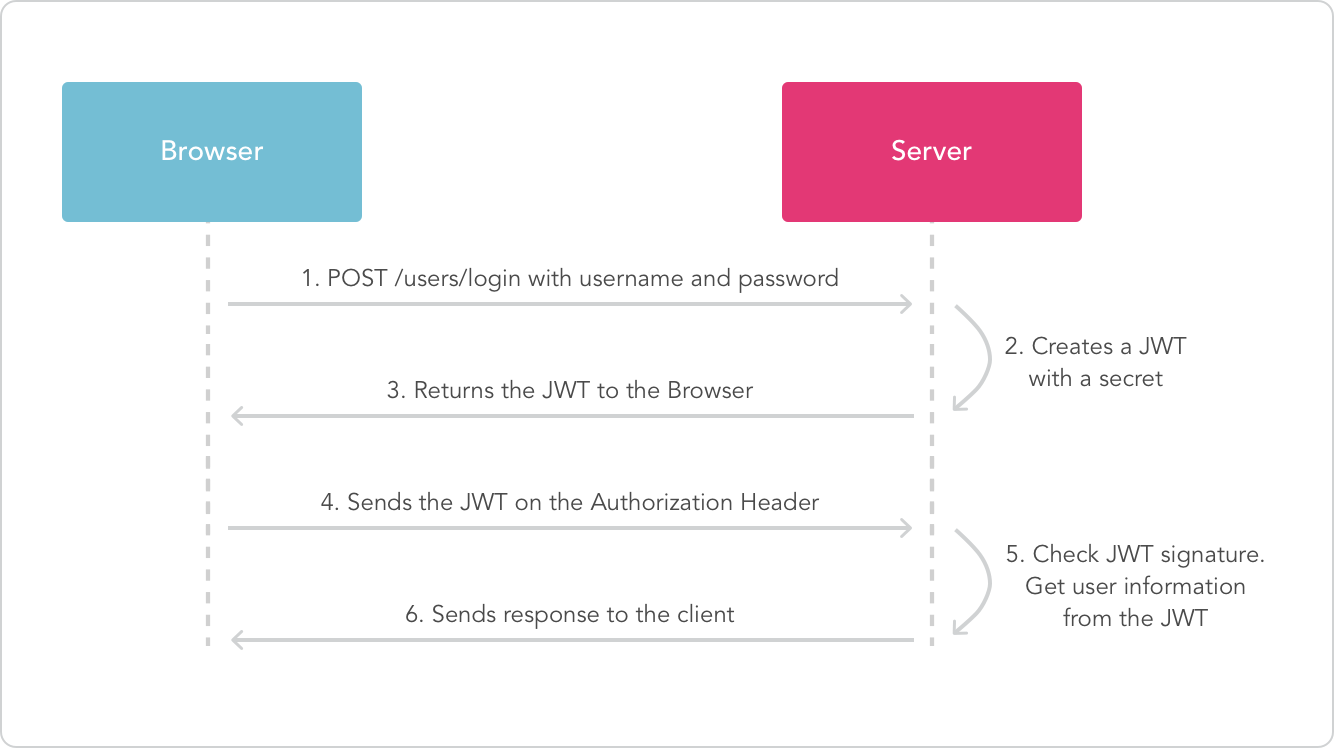
L’idea dietro ai JWT è abbastanza semplice: quando un utente accede, il server genera un token che è essenzialmente una codifica base64 di un semplice oggetto JSON contenente un payload di informazioni, concatenato ad una firma ottenuta generando un hash del suddetto payload con una chiave segreta custodita solo dal server.
Il payload può contenere informazioni utilizzate per autenticare e autorizzare l’utente, come ad esempio il suo ID o i suoi ruoli.
Il token è inviato come risposta al client, ed utilizzato da quest’ultimo per autenticare ogni richiesta API successiva.
Quando il server processa una richiesta in ingresso, preleva il payload dal token e rigenera la firma utilizzando la propria chiave segreta. Se le due firme combaciano, il payload può essere considerato valido e non alterato, identificando in questo modo l’utente.
È importante ricordare che JWT non fornisce nessun tipo di criptazione. Il payload è solo codificato in base64 e inviato in chiaro, quindi se si necessita di nasconderne il contenuto è necessario implementare SSL.
Il seguente schema preso in prestito da jwt.io riassume il processo di autenticazione:
Durante questo processo il server non ha bisogno di accedere a nessun dato memorizzato, quindi ogni richiesta può essere gestita da un processo diverso in una modalità particolarmente efficiente. Nessun dato è salvato in RAM, nessuna operazione di I/O è necessaria, quindi questo approccio risulta particolarmente adatto a scalare.
Archiviazione su S3
Quando si utilizzano più macchine, non risulta possibile memorizzare file generati dagli utenti (come ad esempio delle immagini) direttamente sul filesystem della macchina, in quanto quei file risulterebbero accessibili solo dai processi che risiedono su quello stesso server. La soluzione è di memorizzare tutti questi contenuti su una piattaforma esterna, possibilmente una progettata appositamente come Amazon S3, memorizzando nel proprio DB solo l’URL assoluto che riconduce a tale risorsa.
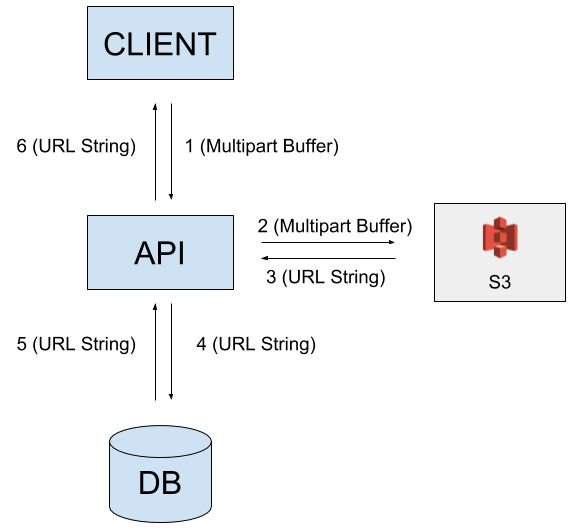
Ogni processo/macchina avrà in questo modo accesso a tale risorsa in modo indipendente. Utilizzare l’SDK ufficiale di AWS per Node.js è abbastanza semplice e permette di integrare il servizio all’interno del proprio applicativo senza particolari difficoltà.
S3 è anche abbastanza economico ed è ottimizzato per il suo scopo, rendendola la soluzione ideale per questo tipo di utilizzo anche in caso di applicativi mono-processo.
Configurare correttamente WebSocket
Se il proprio applicativo utilizza WebSocket per interazioni real-time tra diversi client o tra client e server, è necessario collegare le istanze backend al fine di propagare correttamente messaggi broadcast o messaggi tra due utenti collegati a due istanze differenti.
La libreria Socket.io fornisce un componente particolare per questo scopo, chiamato Socket.io-redis, che permette di collegare le proprie istanze server tramite le funzionalità pub-sub di Redis. Al fine di usare Socket.io in un ambiene multi-nodo stateless, è necessario anche forzare il protocollo di connessione su “websockets”, in quanto il sistema di fallback long-polling richiede un reindirizzamento di tipo “sticky” per funzionare.
Prossimi passi
In questo articolo abbiamo affrontato alcuni semplici aspetti da considerare allo scalare della propria applicazione, i quali possono essere anche considerati come buone pratiche nell’ambito di applicativi a singola istanza. Nel prossimo articolo, ultimo per questa breve serie, saranno affrontati alcuni concetti aggiuntivi per ottenere una maggiore efficienza e migliori performance dalla propria applicazione.