![Good practices for high-performance and scalable Node.js applications [Part 3/3]](https://iquii.com/wp-content/uploads/2018/04/VIRGA_HEADER.jpg "Good practices for high-performance and scalable Node.js applications [Part 3/3]")
Good practices for high-performance and scalable Node.js applications [Part 3/3]
Questo articolo è disponibile in inglese sul nostro canale Medium.
Nei primi due articoli di questa serie abbiamo visto come scalare un applicativo Node.js e cosa considerare lato codice per assicurare un comportamento coerente durante la sua esecuzione. In questo ultimo articolo vedremo alcuni dettagli aggiuntivi che possono migliorare ulteriormente l’efficienza e le performance.
Processi Web e Worker
Come probabilmente saprete, Node.js è in pratica un linguaggio a thread singolo, quindi una singola istanza di un processo può essenzialmente eseguire un’azione per volta. Durante il ciclo di vita di un’applicazione web, vengono eseguiti molti task di natura diversa: gestione di chiamate API, letture e scritture da DB, comunicazioni con servizi di rete esterni, esecuzione di lavori inevitabilmente CPU-intensive, ecc.
Nonostante un utilizzo efficiente della programmazione asincrona, delegare tutte queste azioni allo stesso processo che risponde alle chiamate API può rivelarsi un approccio inefficiente.
Una strategia comune per gestire questo aspetto consiste nella separazione delle responsabilità in due tipi differenti di processo che compongono l’applicazione, tipicamente un processo di tipo Web e uno di tipo Worker.
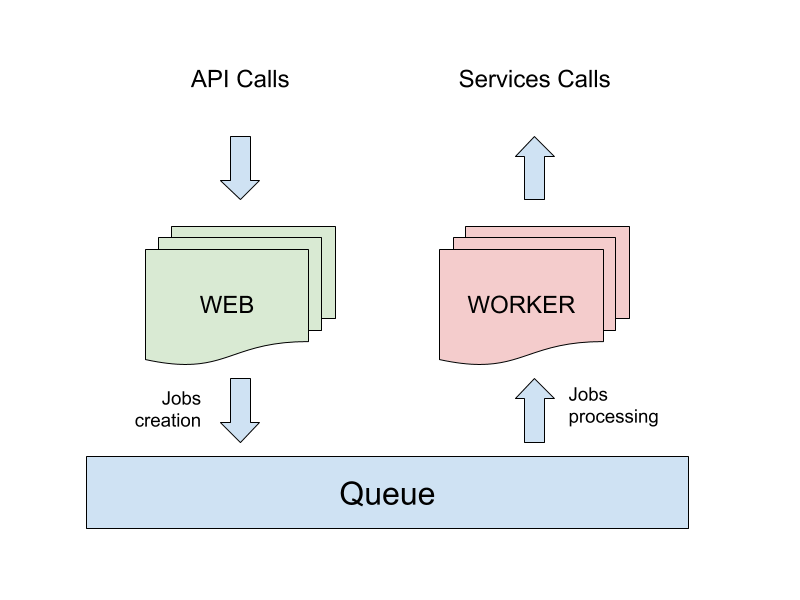
Il processo web è progettato per gestire principalmente le chiamate network in ingresso, e per rispondere a queste nel minor tempo possibile. Ogni volta che un’operazione non bloccante deve essere eseguita, come ad esempio l’invio di un’email o notifica, la scrittura di un log o l’esecuzione di un’azione il cui esito non è necessario per la risposta alla chiamata, il processo web delega l’azione a quello worker.
La comunicazione tra i processi web e worker può essere implementata in modi diversi. Una soluzione comune ed efficiente è l’utilizzo di una coda di priorità, come quella implementata dalla libreria Kue, descritta nel paragrafo successivo.
Uno dei maggiori vantaggi di questo approccio risiede nella possibilità di scalare i processi web e worker in modo indipendente, sulla stessa o su diverse macchine.
Se per esempio l’applicazione in questione è soggetta a traffico intenso con una piccola componente di lavoro computazionale, si possono istanziare più processi web che worker, mentre in caso di molto lavoro generato da poche richieste, si possono ridistribuire le risorse in modo adeguato.
Kue
Per permettere ai processi web e worker di comunicare tra loro, una coda è un approccio flessibile che permette di non doversi preoccupare di complicati metodi di comunicazione tra processi.
Kue è una libreria per code abbastanza comune in Node.js, si basa su Redis e permette di far comunicare tra loro allo stesso modo processi creati sulla stessa macchina o su macchine diverse.
Entrambi i tipi di processi possono creare lavori da mettere in coda, mentre di solito solo i processi di tipo worker sono configurati per poterli portare a termine. Per ogni lavoro si possono impostare diverse opzioni come ad esempio la priorità, il TTL, il ritardo. etc.
Maggiore è il numero di processi worker creati, maggiore è la capacità di calcolo parallelo per eseguire questi lavori.
Cron
È abbastanza comune per un’applicazione avere dei task da eseguire periodicamente. Di solito questo tipo di operazioni sono gestite tramite cron jobs a livello di sistema operativo, dove uno script viene invocato dall’esterno della propria applicazione.
In questo modo risulta necessario un lavoro extra quando si tratta di installare l’applicativo su un nuovo server, rendendo il processo scomodo nel caso lo si voglia automatizzare.
Un modo più comodo di ottenere lo stesso risultato è tramite il modulo cron disponibile su NPM. Questo permette di definire cron jobs all’interno del codice Node.js, rendendoli indipendenti dalla configurazione del sistema operativo.
Seguendo il pattern web/worker descritto in precedenza, un processo worker può creare il cron, il quale invoca a sua volta una funzione che mette periodicamente in coda un nuovo lavoro. L’utilizzo della coda rende il procedimento più pulito e permette di sfruttare tutte le funzionalità messe a disposizione da Kue come la priorità, i retry, ecc.
I problemi iniziano a crearsi quando vengono creati più di un processo worker, in quanto la funzione cron si attiverebbe su ogni processo nello stesso momento, mettendo in coda duplicati dello stesso job che verrebbero eseguiti molteplici volte.
Al fine di risolvere questo problema è necessario identificare un singolo processo worker che eseguirà le operazioni cron.
“Leader election” e cron-cluster
Questo tipo di problema è noto come “leader election”, e per questo scenario specifico esiste un pacchetto NPM che risolve il problema al nostro posto, chiamato cron-cluster.
La libreria espone la stessa interfaccia del modulo cron base, ma durante il setup richiede di utilizzare una connessione Redis per comunicare con gli altri processi worker, ed eseguire l’algoritmo per l’elezione del leader.
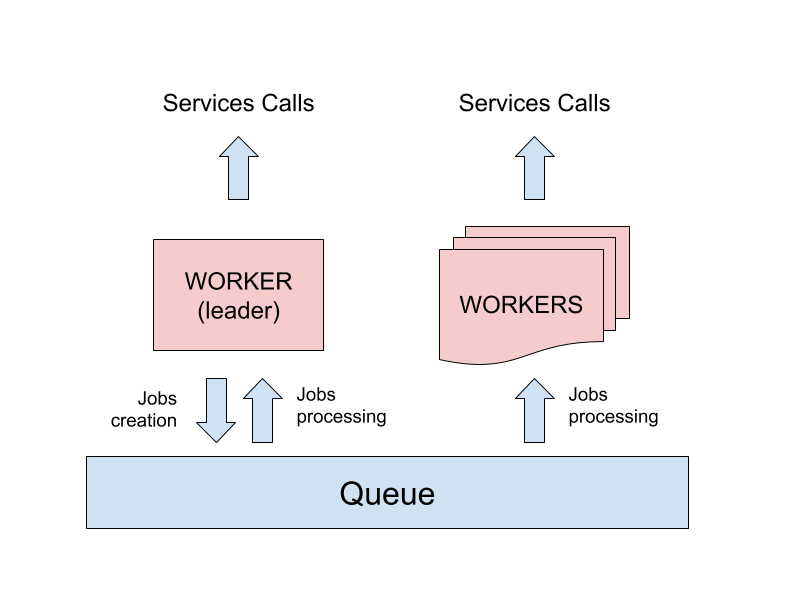
L’utilizzo di Redis come singola fonte di verità permette a tutti i processi di concordare quale tra loro eseguirà le funzioni di cron, e solo una copia di ogni lavoro sarà inserita in coda. In seguito, tutti i processi worker risultano abilitati ad eseguire i lavori inseriti nella coda.
Caching delle chiamate API
Il caching delle chiamate lato server è una strategia comune per migliorare le performance e la reattività delle proprie API, ma è un argomento molto vasto con molteplici possibilità di implementazione.
In un ambiente distribuito come quello descritto in questa serie di articoli, l’utilizzo di Redis per la memorizzazione dei valori in cache è probabilmente il migliore approccio al fine di avere lo stesso comportamento da parte di tutti i nodi.
L’argomento più complesso da affrontare quando si lavora con la cache è la sua invalidazione. La soluzione rapida a questo problema prende in considerazione solamente il tempo, quindi i valori salvati in cache vengono cancellati dopo un tempo di vita prefissato, con lo svantaggio di dover aspettare la pulizia successiva per visualizzare eventuali cambiamenti ai dati nelle risposte.
Se si dispone di più tempo a disposizione, una soluzione più raffinata consiste nell’implementare un’invalidazione a livello applicativo, ripulendo manualmente i valori della cache nel momento in cui vengono aggiornati in DB.
Node.js tra scalabilità e velocità
In questa serie di articoli abbiamo affrontato alcuni argomenti generali riguardo la scalabilità e le performance di applicazioni Node.js.
I vantaggi di questo ambiente di sviluppo, come ad esempio la possibilità di realizzare applicazioni server-side in tempi più ridotti rispetto ai linguaggi di programmazione tradizionali, sono molteplici e rendono questo strumento particolarmente strategico dal punto di vista business. Uno dei maggiori punti di forza è la scalabilità ed efficienza del software, che gli consente di essere applicato sia per piccoli progetti che per applicazioni più grandi in ambito enterprise.
A livello business, l’efficienza di questa tecnologia permette anche di aumentare il traffico gestibile dai singoli server, facendo risparmiare alle aziende risorse in termini di costi hardware. I suggerimenti forniti possono essere interpretati come linee guida che devono ovviamente essere adattate alle particolari esigenze del proprio progetto.
Continuate a seguirci per altri articoli verticali su Node.js e DevOps!